AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
1.What is this paper about?
It proposes an Attentional Generative Adversarial Network (AttnGAN) that allows attention-driven, multi-stage refinement for fine-grained text-to-image generation.
(it propose to use R-precision as a metrics in Text-to-Image model)
2.What’s better than previous paper?
Previous method commonly used approach is to encode the whole text description into a global sentence vector as the condition for GAN-based image generation. But, it prevented the generation of high quality images.
This proposal is to generate to draw different sub-regions of the image by focusing on words that are most relevant to the sub-region being drawn.
3.What are important parts of technique and methods?
It has following two important component.
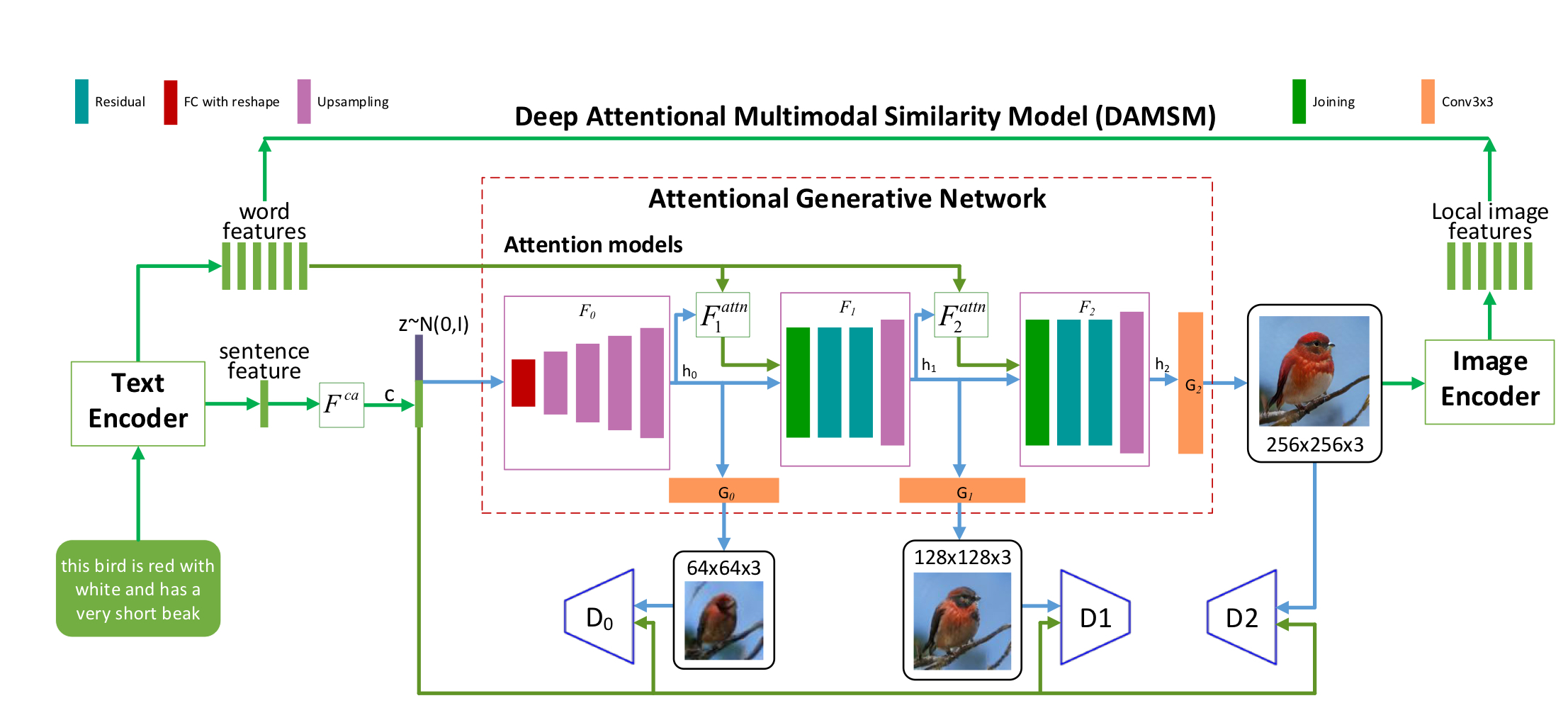
- Attentional Generative Network
It encode the description into a global sentence vector and each word in the sentence is also encoded into a word vector. Low-resolution images were generated from global sentence vectors, and word vectors were used to link images to words to help generate fine-grained images.
- Deep Attentional Multimodal Similarity Model(DAMSM)
It maps sub-regions of the image and word of sentence to commom space and computes the similarity between the generated image and the sentence by using both the global sentence level infomation and the fine-grained word level information. It provides an additional fine-grained image-text matching loss for training the generator.
4.How did they verify it?
On CUB and COCO datasets.
- Quanititative evalution
It is the example result to change the most attended words in text descripiton while keeping the other part.
 The fact that different images matched each text descriptions can be obtained by changing the attended words shows the effectiveness of this method.
The fact that different images matched each text descriptions can be obtained by changing the attended words shows the effectiveness of this method.
- Qualitative evaluation
It evaluates to compare to state-of-the-art methods(GAN-INT, GANWN, StackGAN, StackGAN-v2, PPGN) by using the inception score and R-precision as a metrics.

It significantly outperforms previouse models.
5.Is there a debate?
It lack the ability to generate the photo-realistic image on COCO dataset compared with CUB dataset. It is necessary to discuss how to generate image on dataset that handle a wide variety of images.