Learning What and Where to Draw
1.What is this paper about?
It proposes a new model, the Generative Adversarial What-Where Network (GAWWN), that synthesizes images given instructions describing what content to draw in which location.
2.What’s better than previous paper?
Previous one have so far only used simple conditioning variables such as a class label or a non-localized caption and did not allow for controlling where objects appear in the scene. In contrast, it can generate more realistic and complex scenes by incorporating a notion of localizable objects.
3.What are important parts of technique and methods?
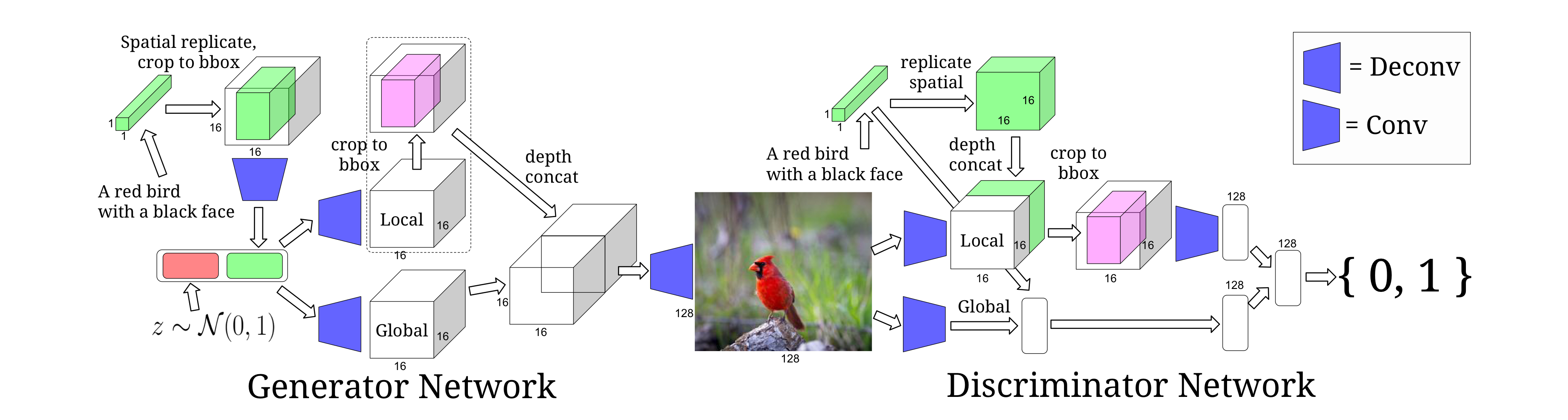
The key is text- and location-controllable image synthesis. It has two ways.
- Bounding-box-conditional text-to-image model
This model is accomplished by controlling the position of the bounding box.
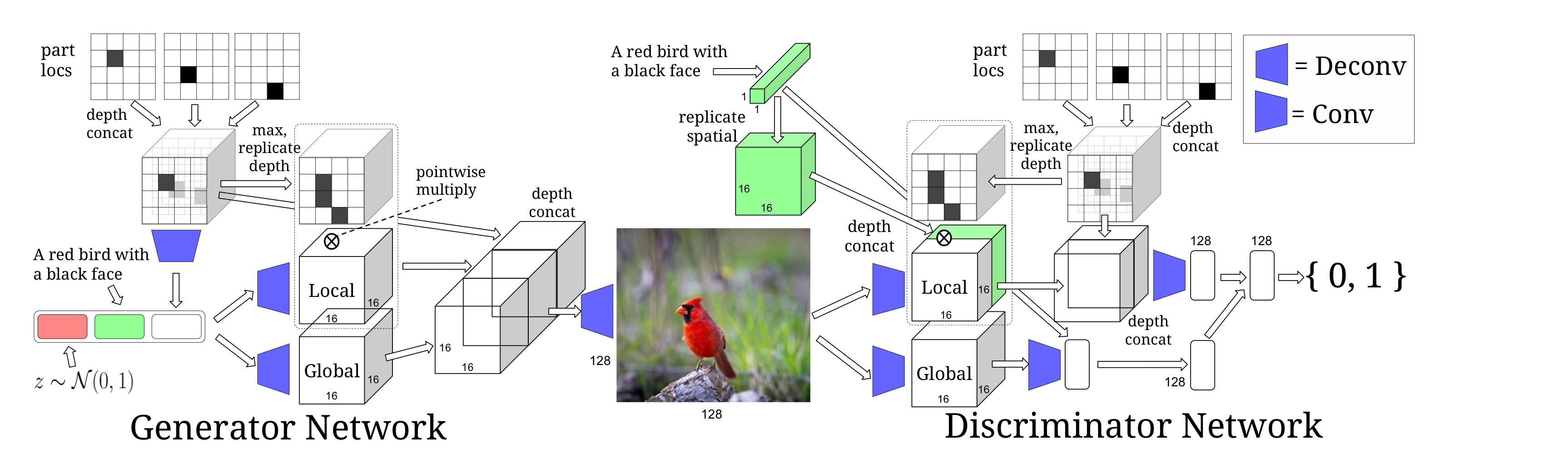
- Keypoint-conditional text-to-image model
This model is accomplished by providing the location keypoints.
4.How did they verify it?
It is valid to generate images from text description by using Caltech-UCSD Birds (CUB) dataset of bird images and MPII Human Pose (MHP) datasets.
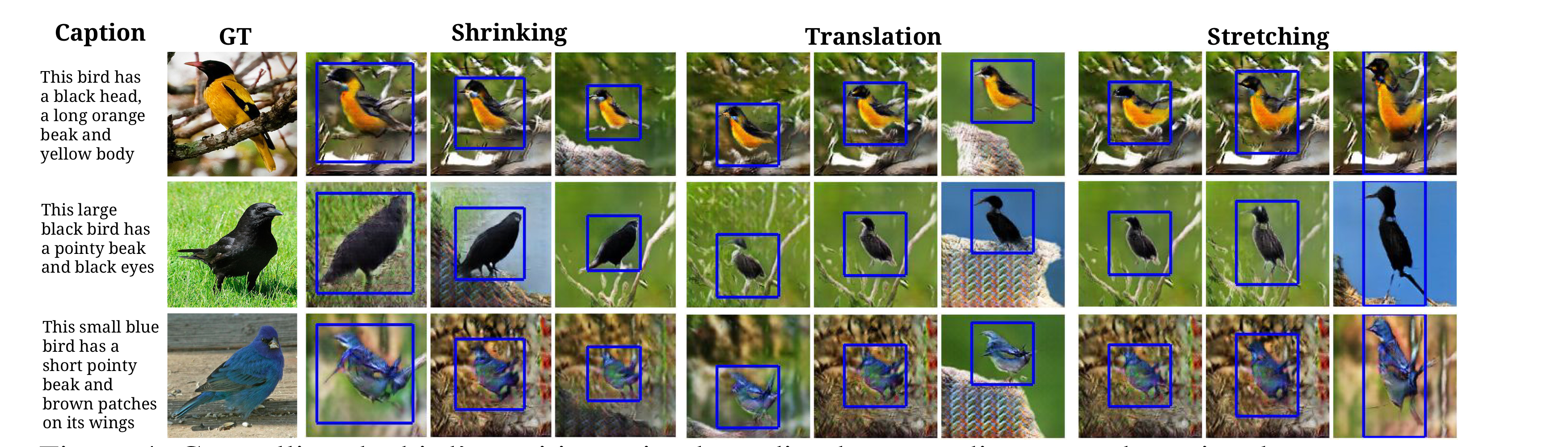
It demondtrate three ways on CUB.
- It shows it can also control the size and aspect ratio of the bird by specifing via bounding box coordinates.
- It shows the case of text-conditional image generation with keypoints fixed to the ground-truth. So it can Control the bird’s position using keypoint coordinates.

- It shows generating both bird keypoints and images from text alone.

It is valid by the above demonstration and further comparison with the previous model(GAN-INT-CLS).
On MHP dataset the expected results were not obtained.
