Generative Adversarial Text to Image Synthesis
1.What is this paper about?
The model to generate images based on detailed visual descriptions using GANs. especially, translating text in the form of single-sentence human-written descriptions directly into image pixels.
2.What’s better than previous paper?
Our model can in many cases generate visually-plausible 64×64 images conditioned on text, but previous model only use GAN for post-processing, our entire model is a GAN, rather only using GAN for post-processing.
The main distinction of our work from the conditional GANs described above is that our model conditions on text descriptions instead of class labels.
3.What are important parts of technique and methods?
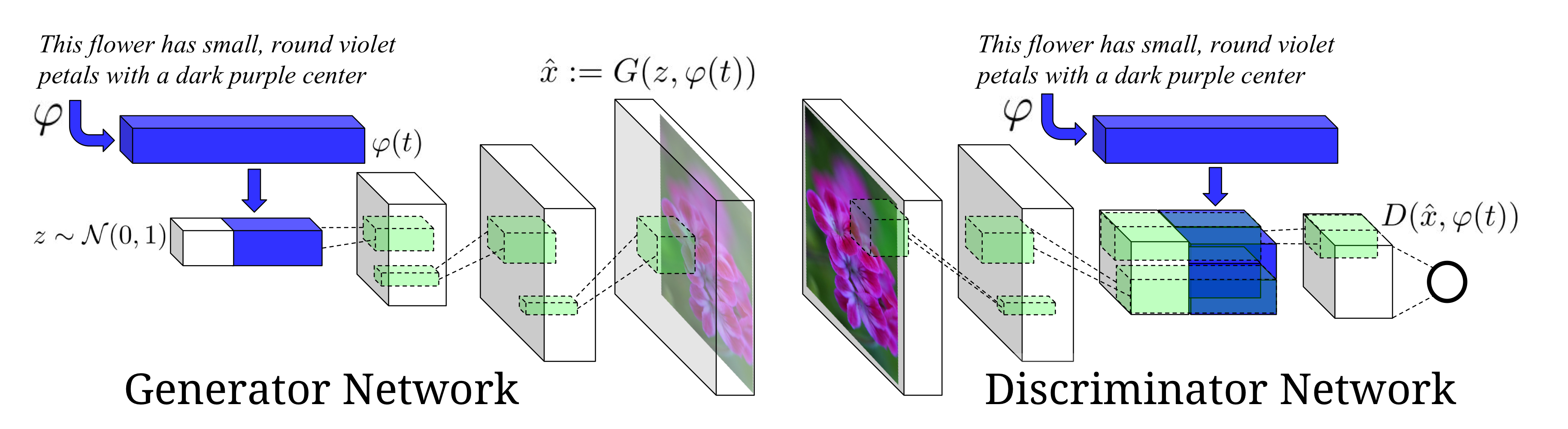
The generator network is optimized to fool the adversarially-trained discriminator into predicting that synthetic images are real. By conditioning both generator and discriminator on side information , we can naturally model this phenomenon since the discriminator network acts as a “smart” adaptive loss function.
We introduce a manifold interpolation regularizer for the GAN generator that significantly improves the quality of generated samples, including on held out zero shot categories on CUB.
4.How did they verify it?
We prove it is valid to make images from description for it using the CUB dataset of bird images and the Oxford-102 dataset of flower images.