Cross-Modal Contrastive Learning for Text-to-Image Generation
1.What is this paper about?
It proposes the Cross- Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses this challenge by maximizing the mutual information between image and text.
2.What’s better than previous paper?
It shows that contrastive learning in the context of text-to- image synthesis and demonstrate that a simple one-stage GAN without object-level annotation can outperform prior object-driven and multi-stage approaches.
3.What are important parts of technique and methods?
It use contrastive learning and following three contrastive loss.
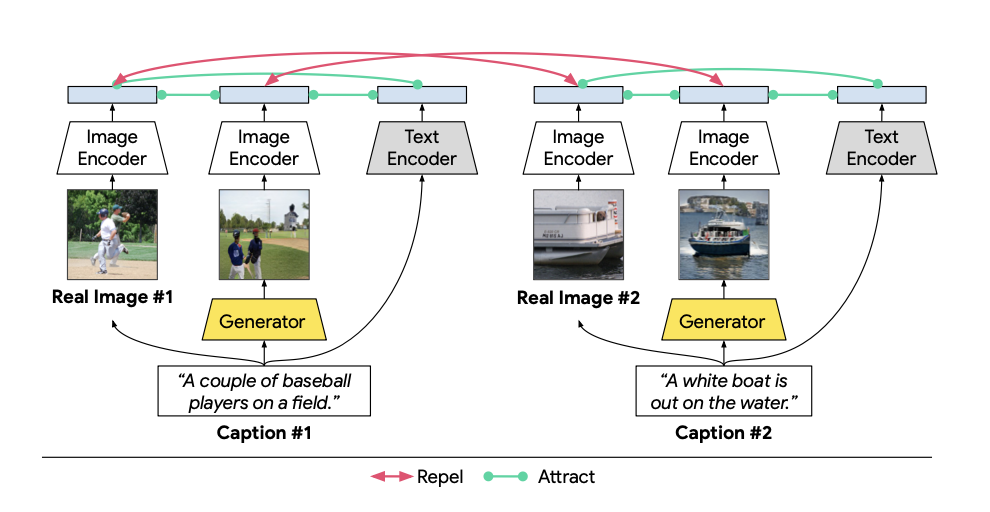
- image to sentence
→ the image should holistically match the description.
- image region to word
→ generated images should match real images when they are conditioned on the same descript.
- image to image
→ individual image regions should be recognizable and consistent with words in the sentence.
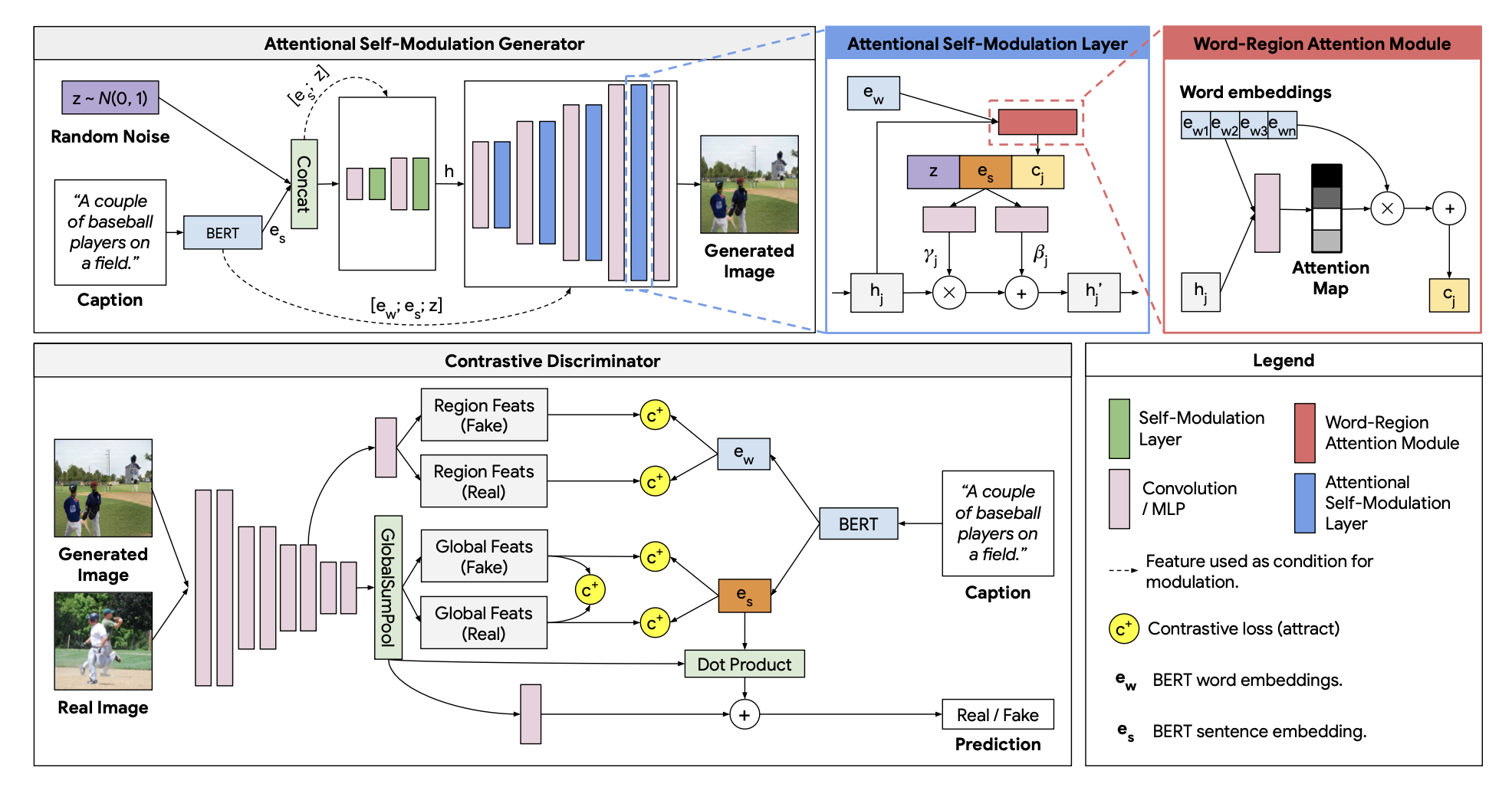
4.How did they verify it?
It valid on the COCO-14, LN-COCO and LN-OpenImages datasets using Inception Score (IS), Frechet Inception Distance (FID) and R-precision, SOA-C and SOA-I as evaluation metrics.
- On the COCO-14 dataset
It shows the validation to compare with three state-of-the-art approaches: CP-GAN, SD-GAN and OP-GAN.
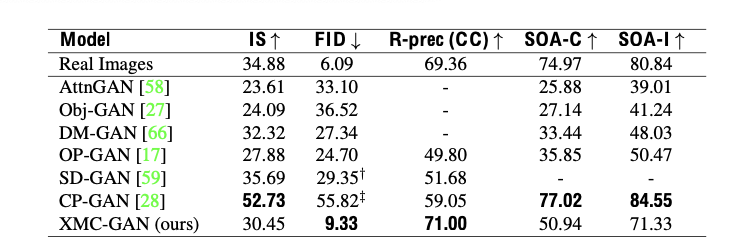
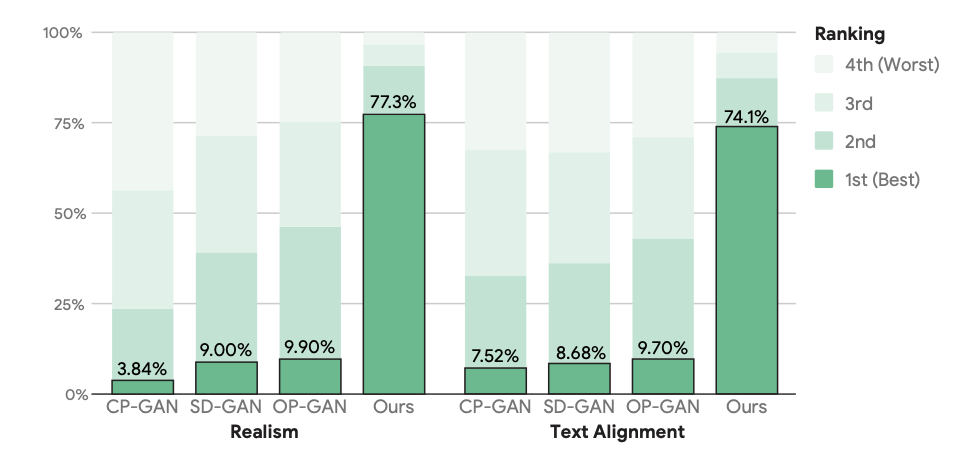
From those result, it shows that FID may be a more reliable metric for measuring text-to-image synthesis quality.
- On the LN-COCO dataset
It shows the validation to compare with three state-of-the-art approaches: TReCS [22], XMC-GAN.
It over-performe previous methods.
- On the LN-OpenImages dataset
It is first result on the LN-OpenImages dataset.