TediGAN: Text-Guided Diverse Face Image Generation and Manipulation
1.What is this paper about?
It proposes TediGAN, a novel framework for multi-modal image generation and manipulation with textual descriptions and the Multi-Modal CelebA-HQ, a large-scale dataset consisting of real face images and corresponding semantic segmentation map, sketch, and textual descriptions.
2.What’s better than previous paper?
Because previous one design a multi-stage architecture, it is defficult to produce high-resolution image. It can produce diverse and high quality images with an unprecedented resolution at 1024*1024 and manipulate image for matching text description. Moreover it can support image synthesis with multi-modal input.(sketches, semantic labels)
3.What are important parts of technique and methods?
It introduces three novel modules.
- StyleGAN Inversion Module
Its encoder is trained on real images instead of synthetic images, which makes it easier to apply to real applications. By recounstrasting in the image space instead of latent space, it can surpervised the strong losses.
- Visual-Linguistic Similarity Learning
It is a visual-linguistic similarity module to project the image and text into a common embedding space, i.e., the W space, like folloing figure.
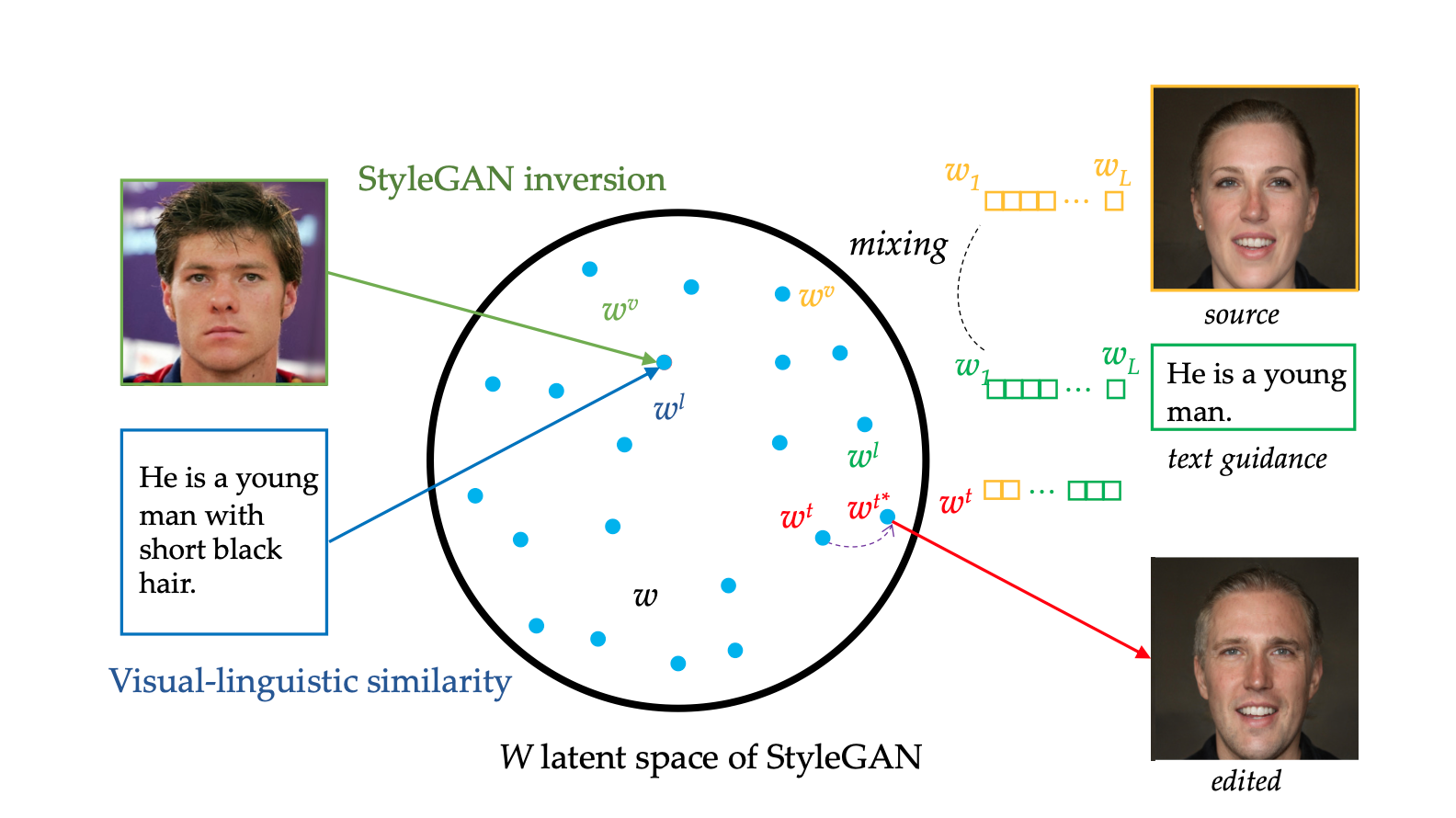
- Instance-Level Optimization
For text-guided image manipulation, it implemented an instance-level optimization module to maintain the locations that match the description, while completely reconstructing the attributes that it does’t match for text.
4.How did they verify it?
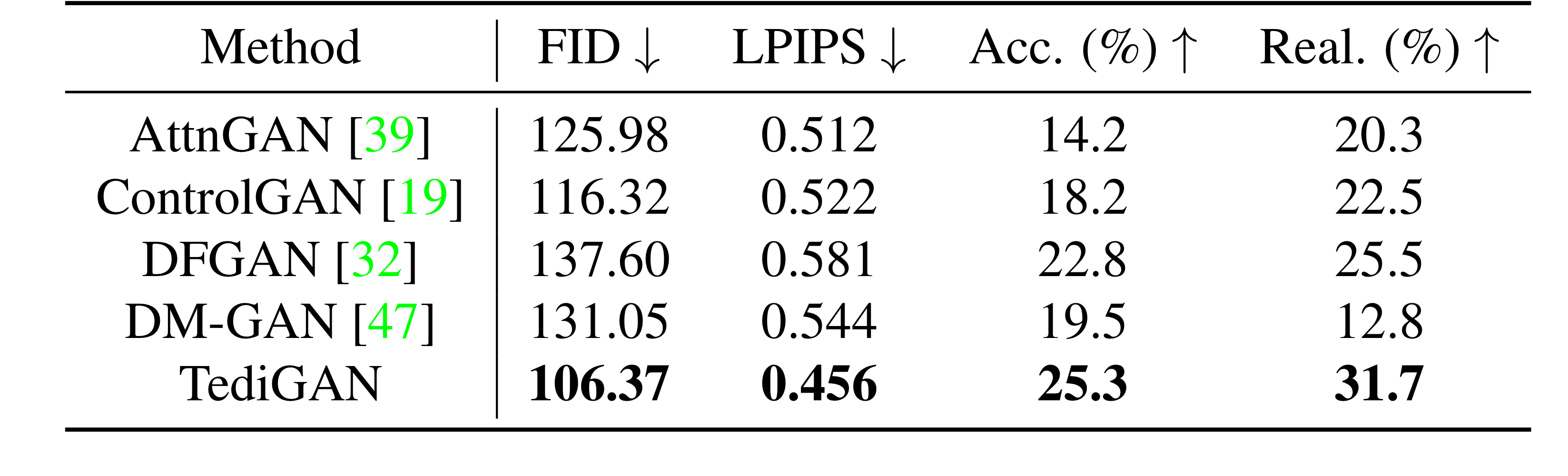
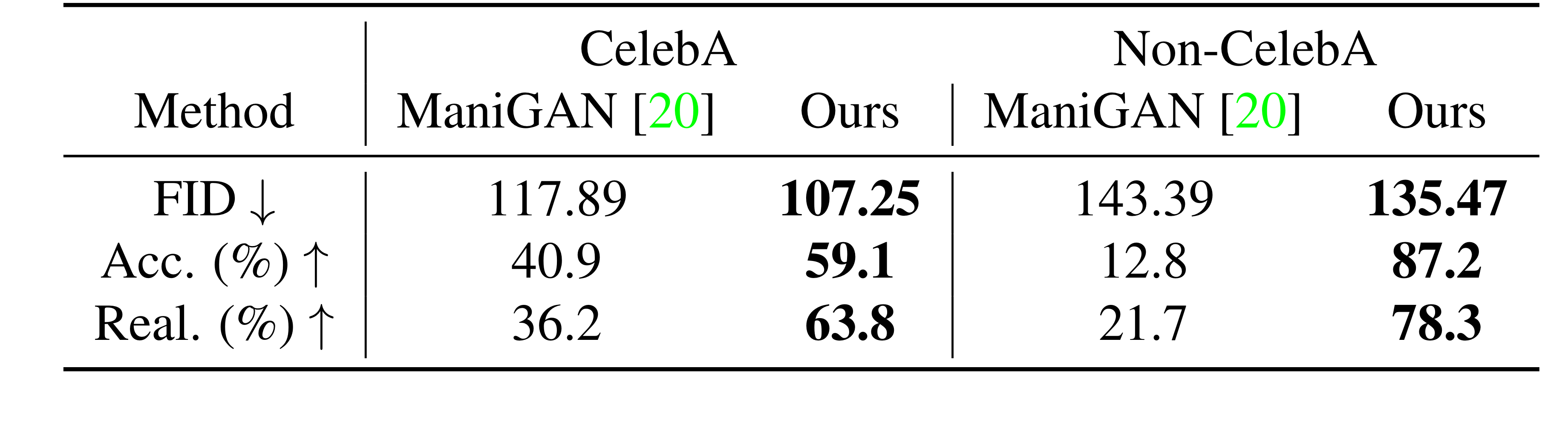
It validated four aspect(image quality, image diversity, accuracy, and realism) to comapre with state-of-the-art model in Text-to-Image synthesize(AttnGAN, ControlGAN, DM-GAN, and DFGAN) and Text-Guided Image Manipulation(ManiGAN). It use Frechet Inception Distance (FID) and Learned Perceptual Image Patch Similarity (LPIPS) as quality and diversity metricses, respectively. In a user study, users are asked to judge which one is the most photo-realistic and most coherent with the given texts.
- Text-to-Image Generation
Quantitative Comparison
Qualitatibe Comparison

- Text-Guided Image Manipulation
Quantitative Comparison
Qualitatibe Comparison

5.Is there a debate?
It has two problem to improve. First, sometime when manipulating the image, non-related attribution are unintentionally change. Second, some attributes, such as hats, necklaces and earrings, are not well represented in its latent space in StyleGAN. So it make the result not sufficient to manipulate these attribution.