TIME: Text and Image Mutual-Translation Adversarial Networks
1.What is this paper about?
Under the GAN frame work, it indecates that G can be boosted substantially by training with D as a language model, which adapts the Transromer to connect between the image features and word embedding. Furthermore it introduce the annealing conditional hinge loss that keep the balances the adversak learing. It can not only ganerate the image from text but make image caption.
2.What’s better than previous paper?
Previous model depends on,
- a pre-trained text encoder for word and sentence embedding.
- an additional image enceode to ascertain image-text consistency.
To address these dependencies, it adapt to train G with D as a laungage model and the novel attention model using Tranformer. And this is the first work to handle bot text2image and image caption in a single model using GAN framework.
3.What are important parts of technique and methods?
Folloing Fig is the overall of this model.
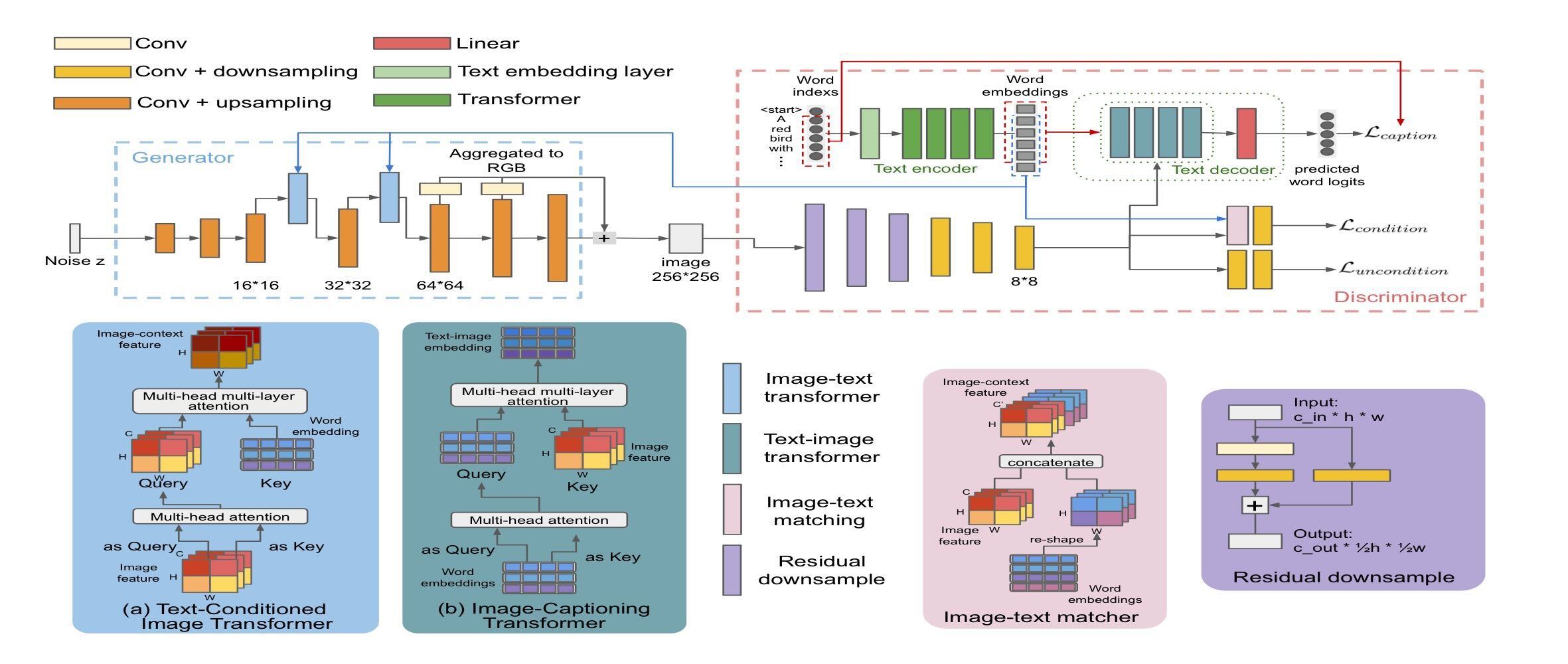
-
Text-Conditioned Image Transformer
- DAMSM
- K: match with fi, V: optimize towards refining fi for a better fit
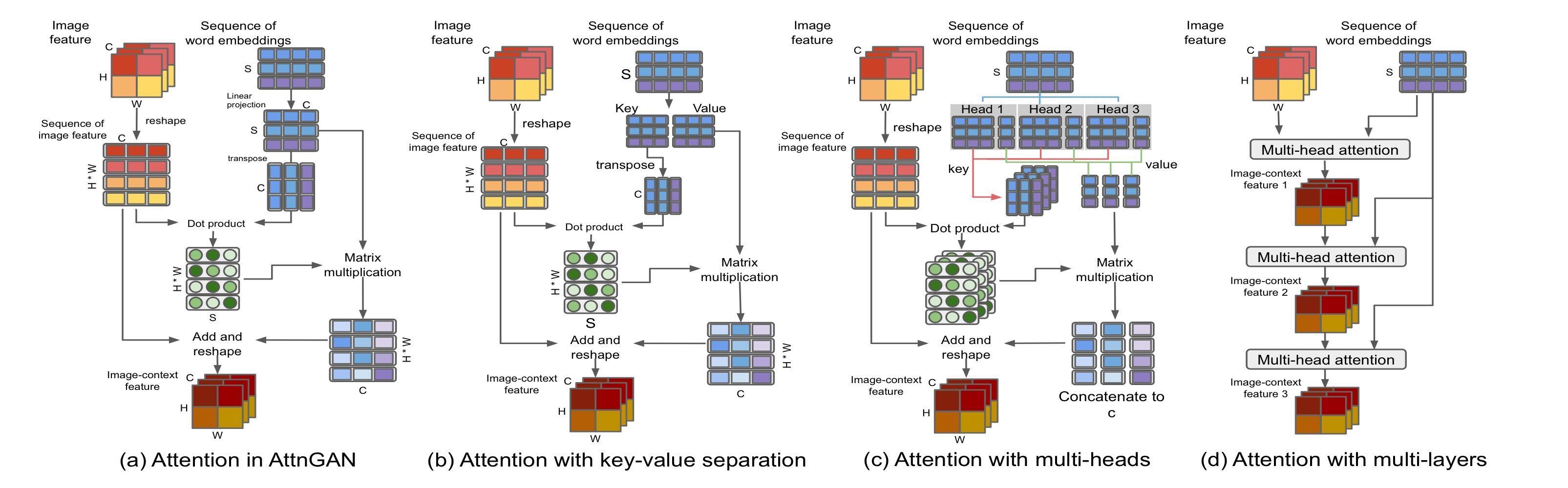
- Adapt the multi-head structure. To replicate the attention module with Transformer make the model flexable by each imag region to account for multiple words.
- stacks the attention layers in a residual structure for a better performance by provisioning multiple attention layers and recurrently revising the learned features.
-
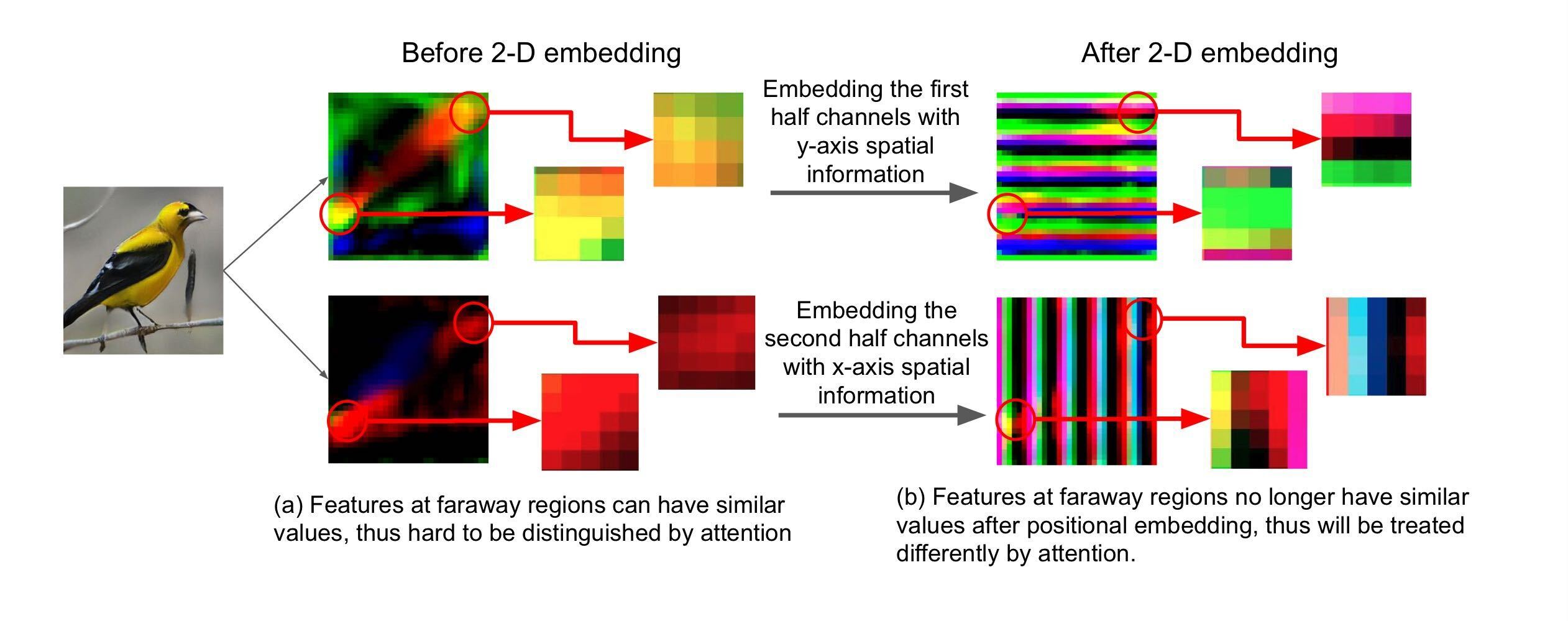
2-D positional encoding
It propose it counter-part to the 1-D positional encodeing in Transformer.
1-D positional is difficult to desinguish the attention, because Transformer has no way to deicern spatial info from the flattened features.
In contrast 1-D ones, it is possible to destinguish the position for attention as following Fig.
- Annealing Image-Text matching loss
To consider that G can learn a good semantic visual translation at early iteration, it introduce its loss for this model.
4.How did they verify it?
It evaluates both task text2image and image-captioning.
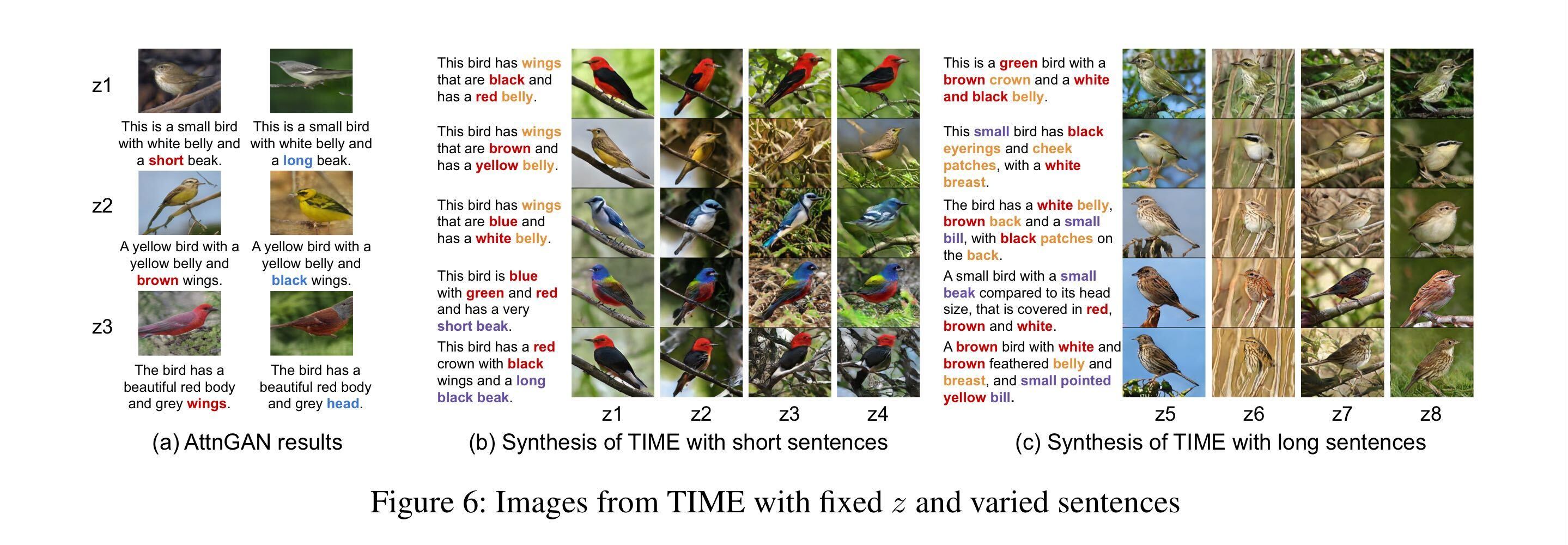

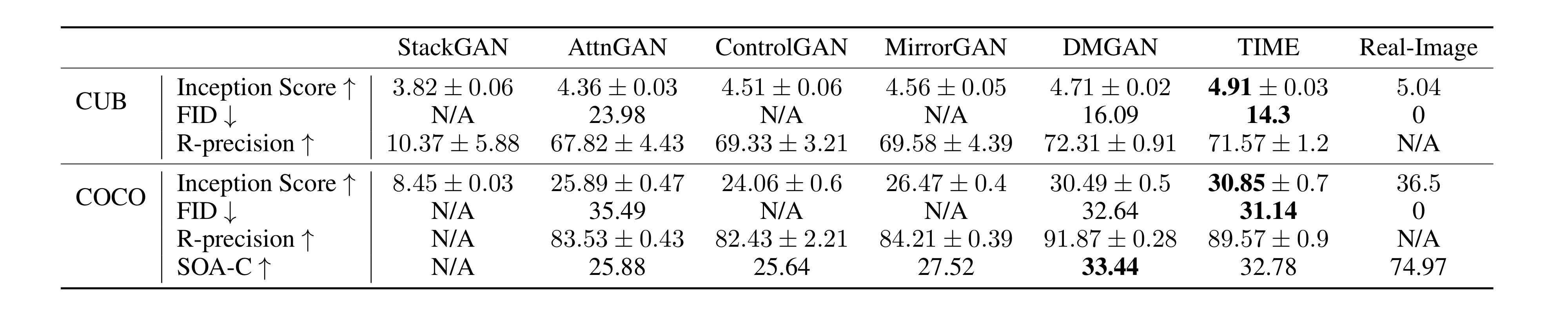
- Text to Image We evaluate the image qulaity on the CUB and COCO datasets. This is the quantitative result by using IS, FID, R-precision, SOA-C as a metrics.
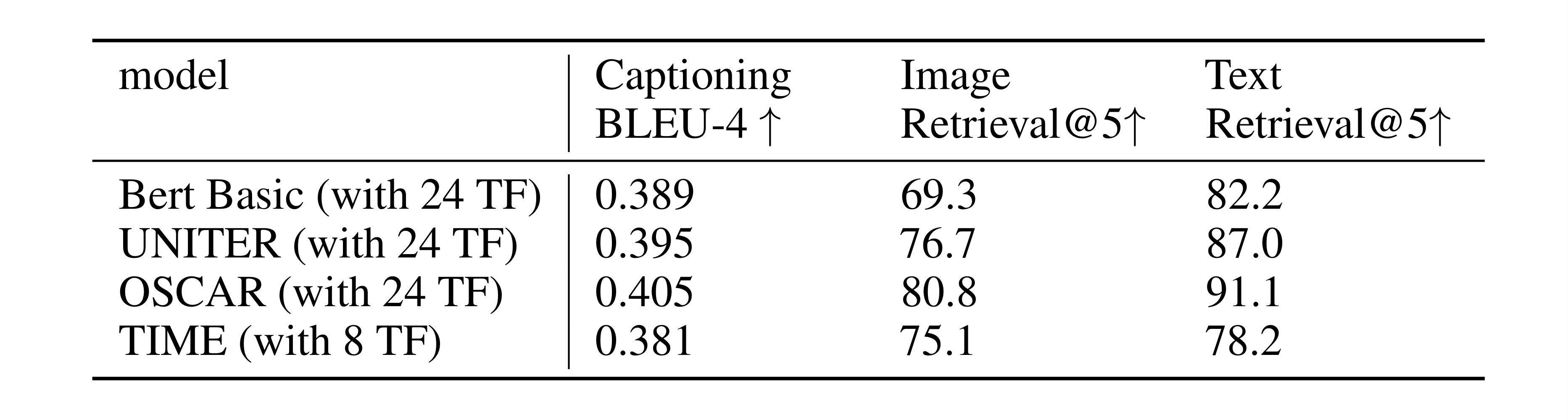
- Image captioning
Compare with state-of-the-art model on the COCO dataset, we evaluate by using BLEU-4, Image-Retrieval@5 and Text-Retrieval@5.
5.Is there a debate?
- Why does it sepalate the y-axis and x-axis spatial info in 2-D positional encoding?