Semantics Disentangling for Text-to-Image Generation
1.What is this paper about?
It proposes Semantics Disentangling Generative Adversarial Network(SD-GAN) that implicitly disentangles semantics to both fulfill the high-level semantic consistency and low-level semantic diversity.
2.What’s better than previous paper?
The previous model lacked the ability to generate similar images from two texts describing the same ground-truth. To address this issue, it can generate consistency image in spilte of retainning semantic diversities and details.
3.What are important parts of technique and methods?
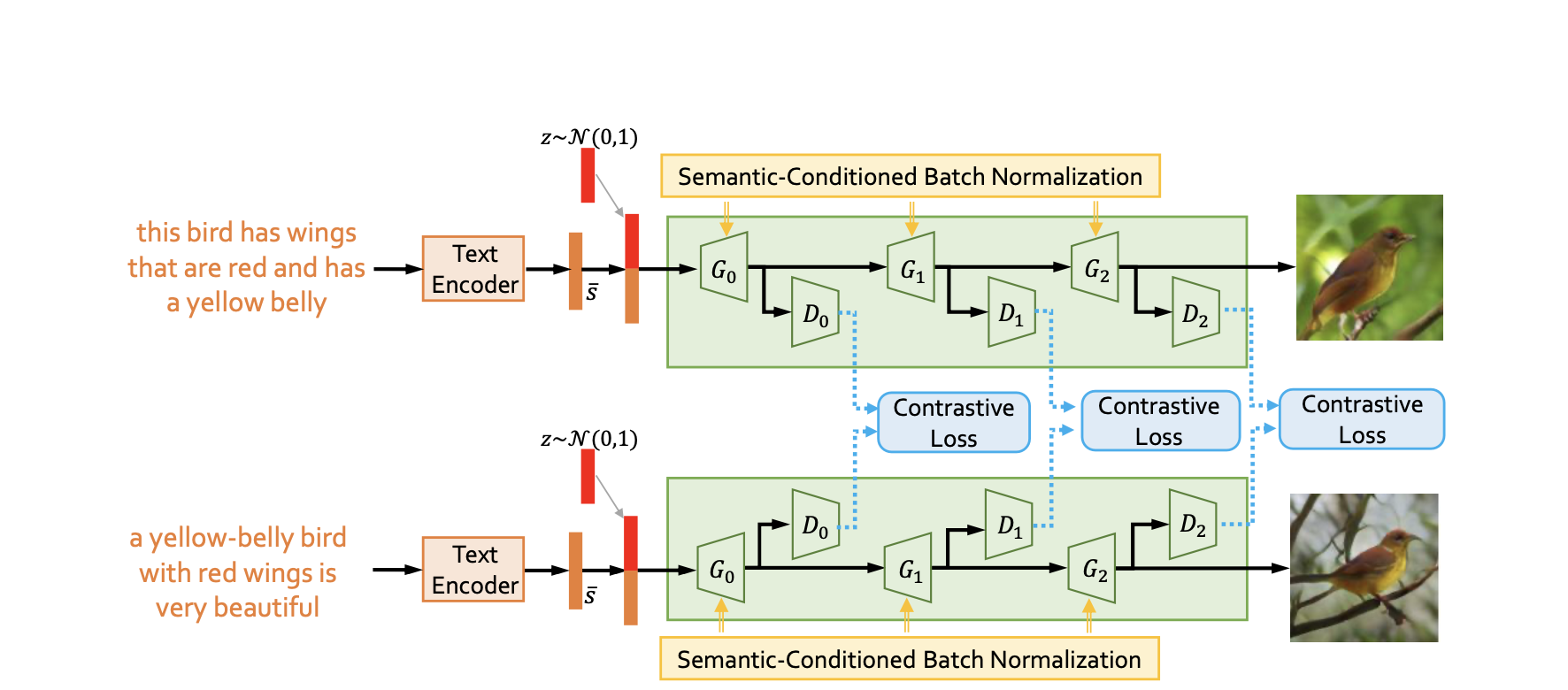
- Siamese Structure with Contrastive Losses
It distills semantic commons from the linguistic description to keep generate image consistency under expression variants.
- Semantic-Conditioned Batch Normalization(SCBN)
The purpose of SCBN is to reinforce the visual-semantic embedding in the feature maps of the generative networks and complements to the Siamese structure introduced which only focuses on distilling semantic commons but ignore the unique semantic diversities in the text.
4.How did they verify it?
It is evaluated on CUB and MS-COCO datasets.
- Quantitative evaluation For metrics evaluation
It uses inception score as metrics and compare with state-of-the-art methods.
For human evaluation
50 text descriptions for each class in the CUB test set and 5000 text descriptions in the MS-COCO test set are randomly selected, and 50 users given the same description are asked to rank the results in different ways. It compares with StackGAN and AttnGAN.
- Qualitative evaluation
It evaluated to generate two images from two text descriptions describing the same ground-truth image and compare with StackGAN and AttnGAN.
All of evaluations show this model outperform state-of-the-art models. By conducting an ablation study, the effectiveness of each architecture and contrastive loss was demonstrated.