Mask R-CNN
1.What is this paper about?
It proposes a conceptually simple, flexible, and general framework, which extends Faster R-CNN, for object instance segmentation.
Using its proposal, it can easily be extended to human pose estimation.
2.What’s better than previous paper?
It show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding- box object detection, and person keypoint detection. Futermore, it simple to train and run at 5 fps.
3.What are important parts of technique and methods?
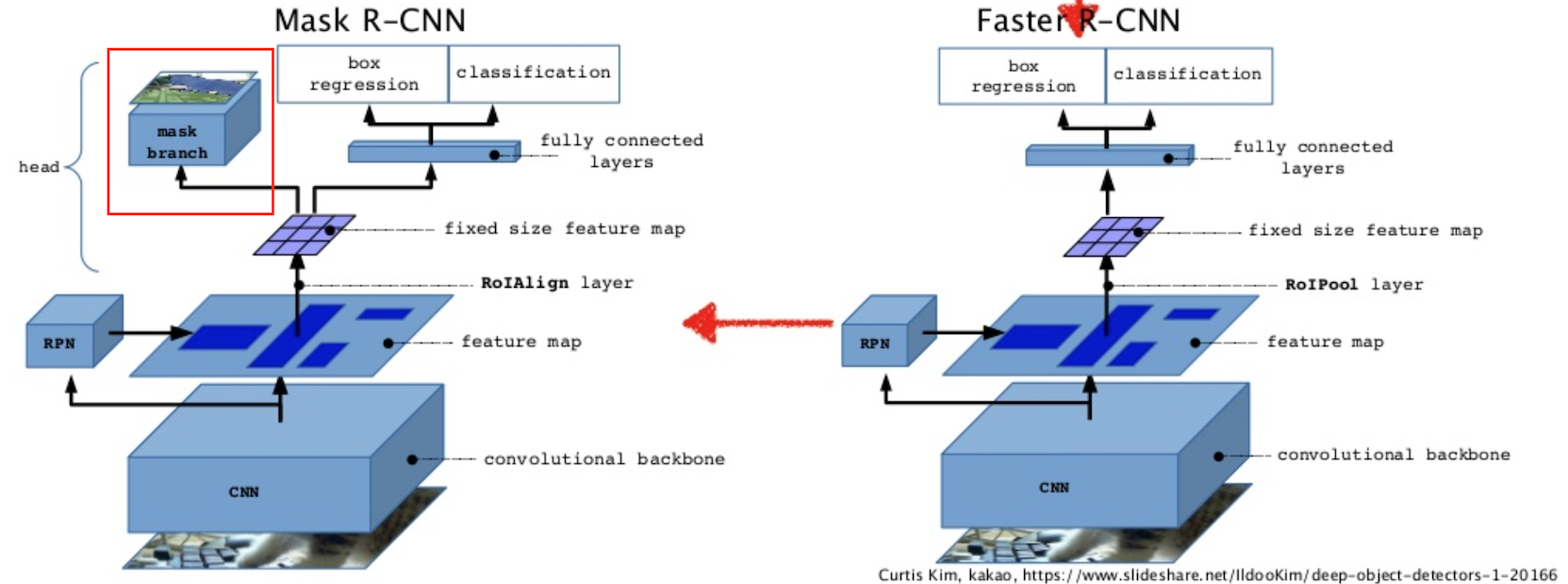 引用元: https://www.slideshare.net/windmdk/mask-rcnn
引用元: https://www.slideshare.net/windmdk/mask-rcnn
As shown in the figure above, Instant segmentation can be performed by adding a branch to Faster R-CNN. But, Faster R- CNN was not designed for pixel-to-pixel alignment between network inputs and outputs. To fix the misalignment, it proposes a simple, quantization-free layer, called RoIAlign, that faithfully preserves exact spatial location
4.How did they verify it?
It is validated by comparing of Mask R-CNN to the state-of-the-art along with comprehensive ablations on the COCO dataset. It uses AP (averaged over IoU thresholds), AP50, AP75 , and APS , APM , APL (AP at different scales) as a metrics.
It shows all instantiations of its model outperform baseline variants of previous state-of-the-art models.
It show the effectiveness of our new proposal from the Ablation Experiments.