DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
1.What is this paper about?
It proposes the DiffusionCLIP which perform manipulate the image according the text using the diffusion models. It is possible to manipulate the various kind of image fastly.
2.What’s better than previous paper?
Previus model mainly use the GAN inversion model. However they have limitation that it is hard to reconstruct image with novel pose, view and highly variable contents.
This model is possible to manipulate not only trained but also unseen domain, so it overcome the problem mention above.
3.What are important parts of technique and methods?
This is the overall of DiffusionCLIP.
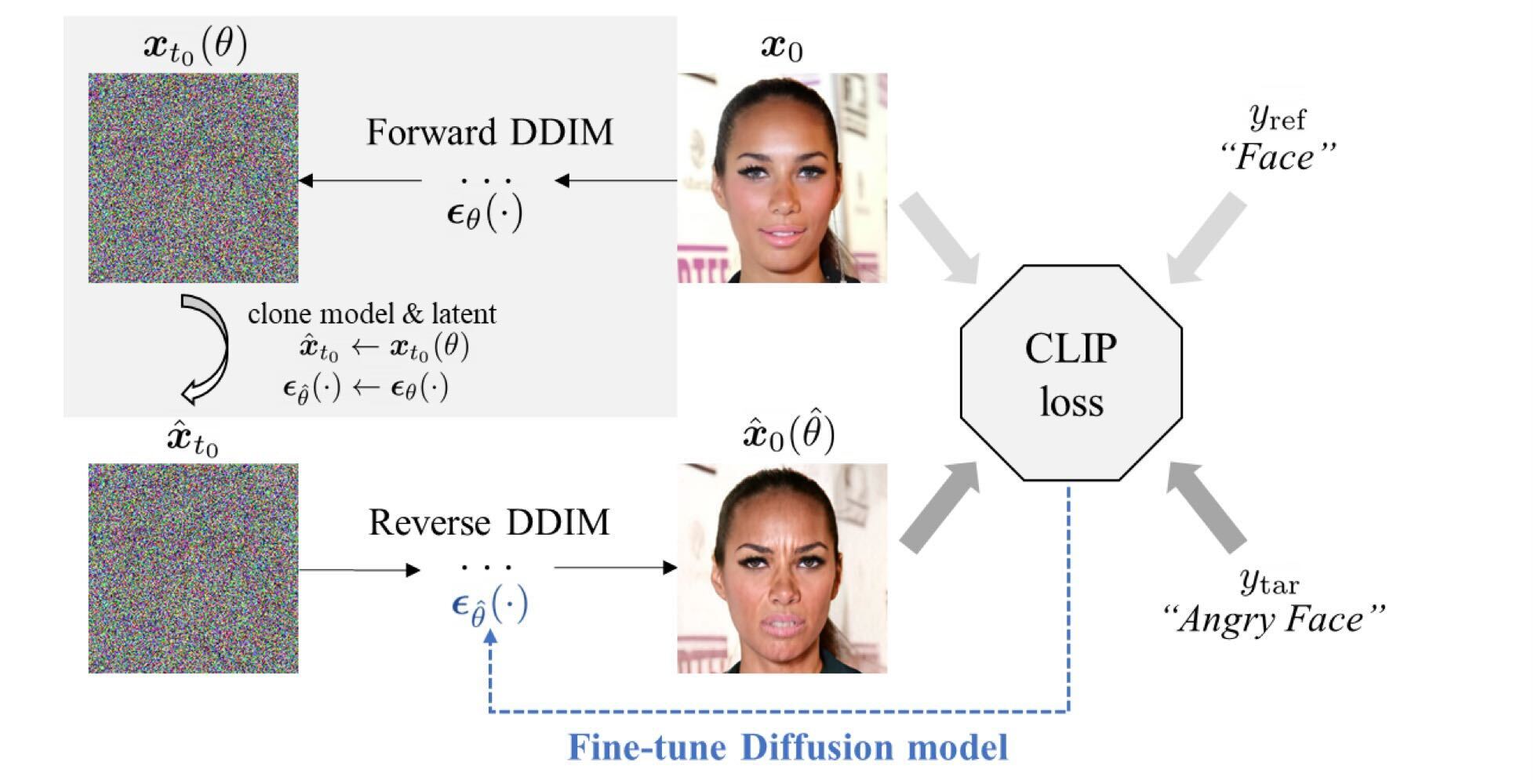
It introduce the two type of losses: directional CLIP loss and Identity loss in reverse diffusion proccess to controll the attribution.
-
Directional CLIP loss It induces the direction between the embeddings of the reference and generated images to be aligned with the direction between the embeddings of a pair of reference and target texts in the CLIP space.
-
Identity loss To prevent the unwanted changes and preserve the identity of the object.(for face image manipulation, it adapt face indentity loss.)
4.How did they verify it?
It performs the quantitative comparision with SOTA text-guided image manipulation methods, TediGAN, StyleCLIP and StyleGAN-NADA.
