ManiTrans: Text-Guided Image Manipulation
1.What is this paper about?
初めて、Transformer-basedのtext-guided image manipulation modelである。 さらに、CLIPを用いた、semantic loss functionと2つのpre-trained modelを用いたsemantic alignment moduleを導入して、SOTAを達成した。
2.What’s better than previous paper?
過去モデルでは、DAMSM(AttnGAN)などのattentionが使われていたが、Transfomerを導入することで、より精度の高いattentionが行えるようになった。 さらに、CLIPを使用したLossを導入することで、他クラスのCOCOデータセットでも高い精度を実現した。 さらに、textに関連しない領域の情報を保持するために、manipulation modelの前に、detectionして領域を分けることで、背景情報の不本意な修正をなくした。
3.What are important parts of technique and methods?
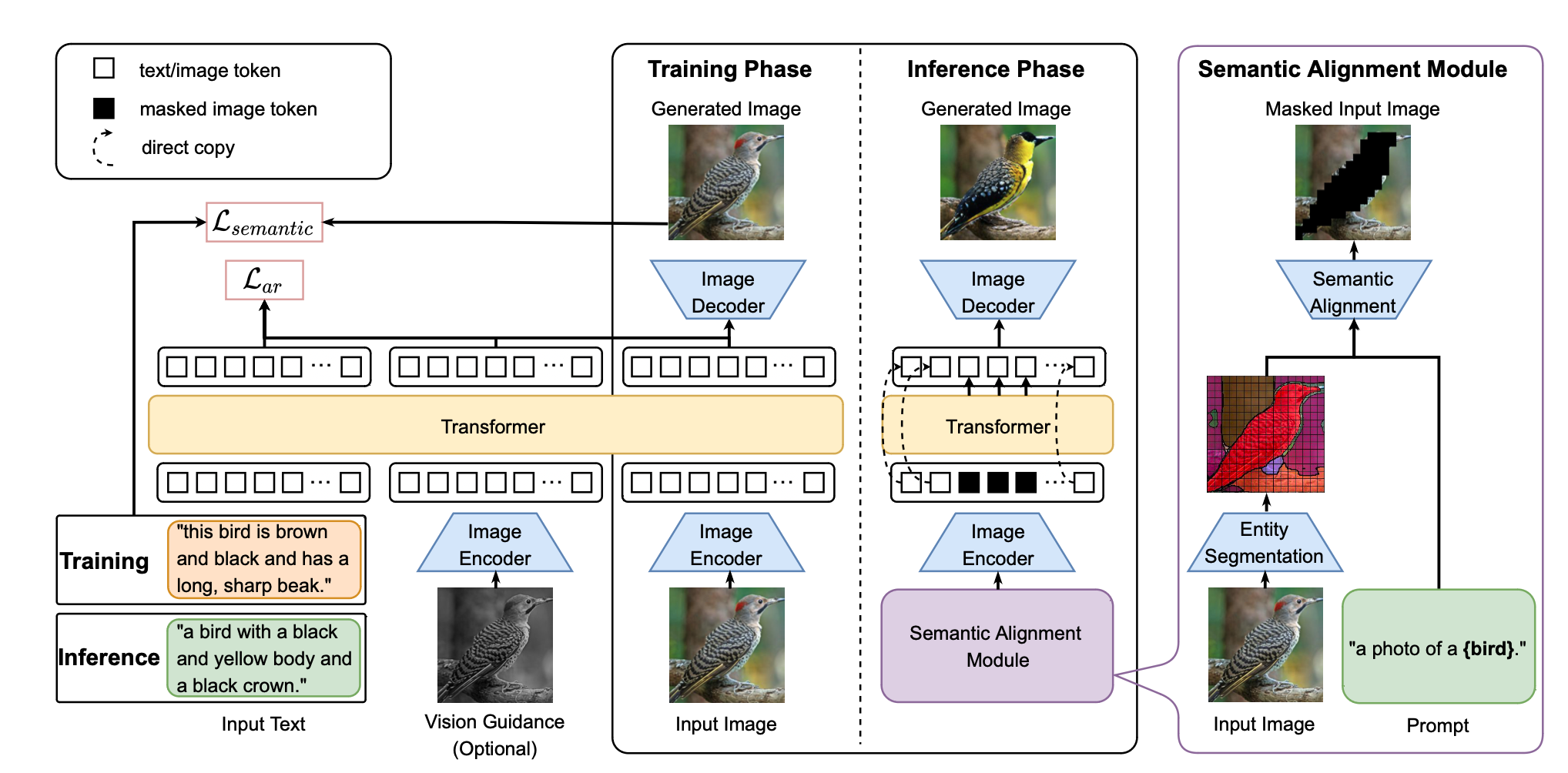
VAEを用いて、出力画像を入力画像が同じになるように学習し、Transoformerを使用して、textとimage(token)の結びつきを学習させた。
さらに、Inferenceの時に、事前にsegmentation detectionと、テキスト関連部を出力するpre-train model(今回は、CContinuous Refinement Model(CRM)とFILIP)を使用することで、text関連部のみをdetectし、その情報を入力することで、image manipulationの精度を向上させた。
4.How did they verify it?
使用したデータセット: Oxford(花), CUB(鳥), COCO(色々) 使用したmetrcs:
- Inception Score(IS) for quality of image.
- CLIP-score for visual-semantic alignment - cos similarity between embedding extracted with CLIP
- Recall@N for image-to-text retrieval - 正解に1対して、不正解99から、cos simでsortedして上から何番目かを計算。
Quantitative evalution
Qualitative evalution

また、CUBとOxfordの融合データセットを作ることで、 花→鳥、鳥→花のimage manipulationgaが可能になった。

5.Is there a debate?
生成前のbackgroundと生成後のbackgroundの変化がある。 → lossをかませるか、WACVの方法でやれば、まあ精度は改善できると思われる。 でも、imagenといい、最近のimage manipulation modelは、多少のテキストに関連していない部分を許容する動きなのかな?(背景画像より、realityのあるimageって感じ?)
CUBとOxfordの画像をmixの仕方などが知りたいが、何も書かれていない。 → codeの公開はよーーーー
6.My interest paper in this paper
- CogView: Mastering Text-to-Image Generation via Transformers
- ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
- Taming Transformers for High-Resolution Image Synthesis
- Zero-Shot Text-to-Image Generation