ManiGAN: Text-Guided Image Manipulation
1.What is this paper about?
It proposes a novel generative adversarial network (ManiGAN), which contains two key components: text-image affine combination module (ACM) and detail correction module (DCM).
2.What’s better than previous paper?
The previous methods to fuse text and image information are to directly concatenate image and global sentence features along the channel direction. It leads to inaccurate and coarse modification, also fails to reconstruct text-irrelevant contents. Its proposal can generate high-quality new attributes matching the given text, and at the same time effectively reconstruct text-irrelevant contents of the original image.
It over-perform previous method as bellow.

3.What are important parts of technique and methods?
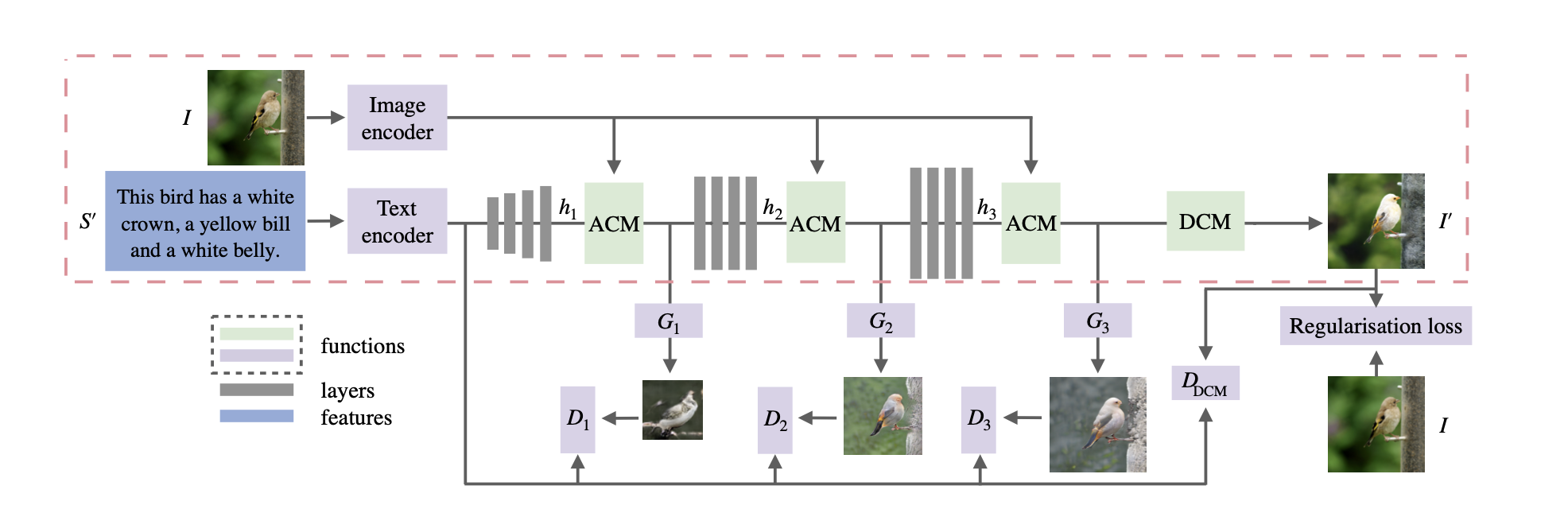
- Text-Image Affine Combination Module(ACM)
it is that text and image features collaborate to select text-relevant regions that need to be modified, and then correlate those regions with corresponding semantic words for generating new visual attributes semantically aligned with the given text description.
- Detail Correction Module(DCM)
It can rectify the image generated by using ACM mismatched attributes and complete missing contents.
By using these proposal it can over-perform.
4.How did they verify it?
It is evaluated on the CUB bird and COCO datasets, comparing with two state-of-the-art approaches SISGAN and TAGAN on image manipulation using natural language descriptions using inception score (IS) and manipulative precision (MP) as metric.
From this result it overpaform state-of-the-art approaches.