Explain Images with Multimodal Recurrent Neural Networks
1.What is this paper about?
A multimodal Recurrent Neural Network (m-RNN) model for generating novel sentence descriptions to explain the content of images.
The model consists of two sub-networks.
- A deep recurrent neural network for sentences
- A deep convolutional network for images
These two sub-networks interact with each other in a multimodal layer to form the whole m-RNN model.
2.What’s better than previous paper?
Previous works can only label the query image with the sentence annotations of the images already existing in the datasets, thus lack the ability to describe new images that contain previously unseen combinations of objects and scenes.
Our work can predict combinations of objects and scenes and perform at the state-of-the-art in three tasks: sentence generation, sentence retrieval given query image and image retrieval given query sentence.
3.What are important parts of technique and methods?
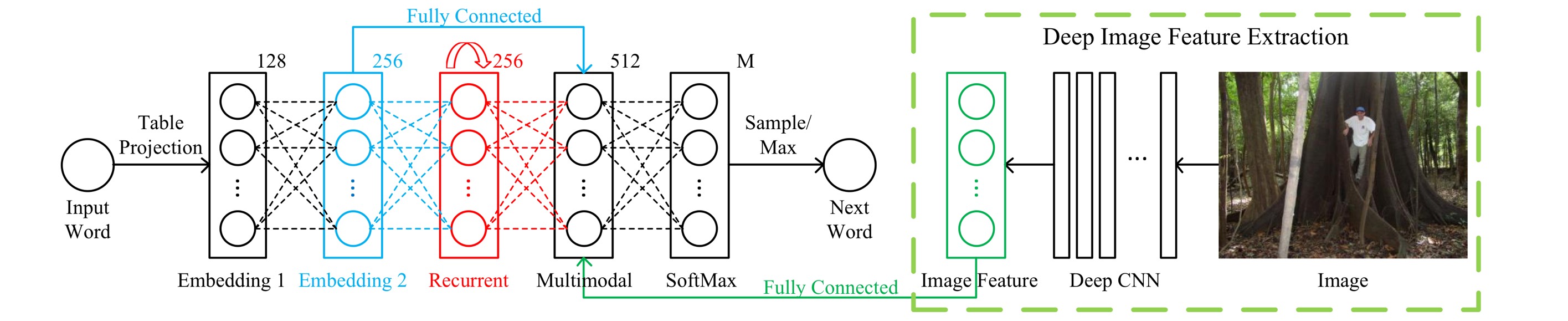
The whole m-RNN have three part.
- A language model part This part learns the dense feature embedding for each word in the dictionary and stores the semantic temporal context in recurrent layers.
- An image part This part contains a deep Convolutional Neural Network (CNN) which extracts image features.
- A multimodal part This part connects the language model and the deep CNN together by a one-layer representation.
The m-RNN model is much deeper than the simple RNN model. It has six layers in each time frame: the input word layer, two word embedding layers, the recurrent layer, the multimodal layer, and the SoftMax layer.
4.How did they verify it?
we validate our model on three benchmark datasets: IAPR TC-12, Flickr 8K, and Flickr 30K. we show that our method significantly outperforms the state-of-the-art methods in both the task of generating sentences and the task of image and sentence retrieval when using the same image feature extraction networks. we adopt sentence perplexity and BLEU scores.