Context-Aware Group Captioning via Self-Attention and Contrastive Features
1.What is this paper about?
This paper show three proposal.
-
New task of context-aware group captioning, which aims to describe a group of target images in the context of another group of related reference images.
-
A framework combining self-attention mechanism with contrastive feature construction to effectively summarize common information from each image group while capturing discriminative information between them.
-
New dataset which we grouped the images and generated the group captions based on single image captions using scene graphs matching.
2.What’s better than previous paper?
-
Previous paper mostly focus on generating captions for a single image. On the other hand, Our work focuses on the novel setting of context-based image group captioning which aims to describe a target image group while leveraging the context of a larger pool of reference images.
-
By using existing individual image captioning task, it can’t solve new task context-aware group captioning because it only caption each image individually and then summarize the perimage captions.
-
Exsiting dataset Conceptual Captions dataset’s captions are often long and sometime noisy. On the other hand new dataset Stock Captions dataset is characterized by very precise, short and compact phrases.
3.What are important parts of technique and methods?
- There are two key task(feature aggregation and group contrasting) to solve new task.
-
It propose to use the transformer architecture for former task. By learning the self-attention grid, the model can detect the prominent features as each element in the set can “vote” for the importance of the other elements through the attention mechanism.
-
It can resolve the task in the following way.First it learn the difference between two groups of images and to capture their similarity. Second we can deduce discriminative representation by subtracting this similarity portion from the two features.
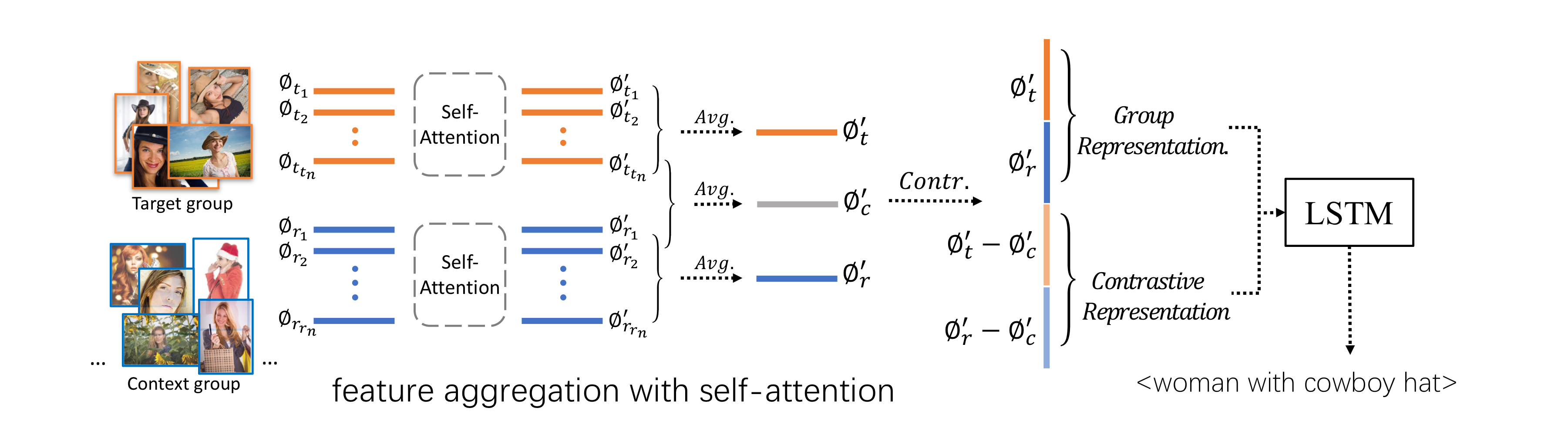
-
4.How did they verify it?
-
To test the quality of our data and compare our two datasets(existing and new dataset), we conduct a user study by randomly selecting 500 data samples (250 from each dataset) and ask 25 users to give a 0-5 score for each sample.
-
It validate our model on Conceptual Captions dataset and Stock Captions datase. It adopt metrics normally used for image-caption, including BLEU, CIDER, METEOR and ROUGE, in addtion metrics, Word-by-word accuracy(WordAcc), worderror rate(WER), that specifically assess word-based accuracy.