Better Captioning with Sequence-Level Exploration
1.What is this paper about?
It proposes to add a sequence-level exploration term to the current sequence-level learning model to boost recall.
2.What’s better than previous paper?
Previous model is equivalent to only optimize the precision side and therefore overlooks the recall side.
It models to explore more plausible captions in the training and takes both the precision and recall sides of generated captions into account.
3.What are important parts of technique and methods?
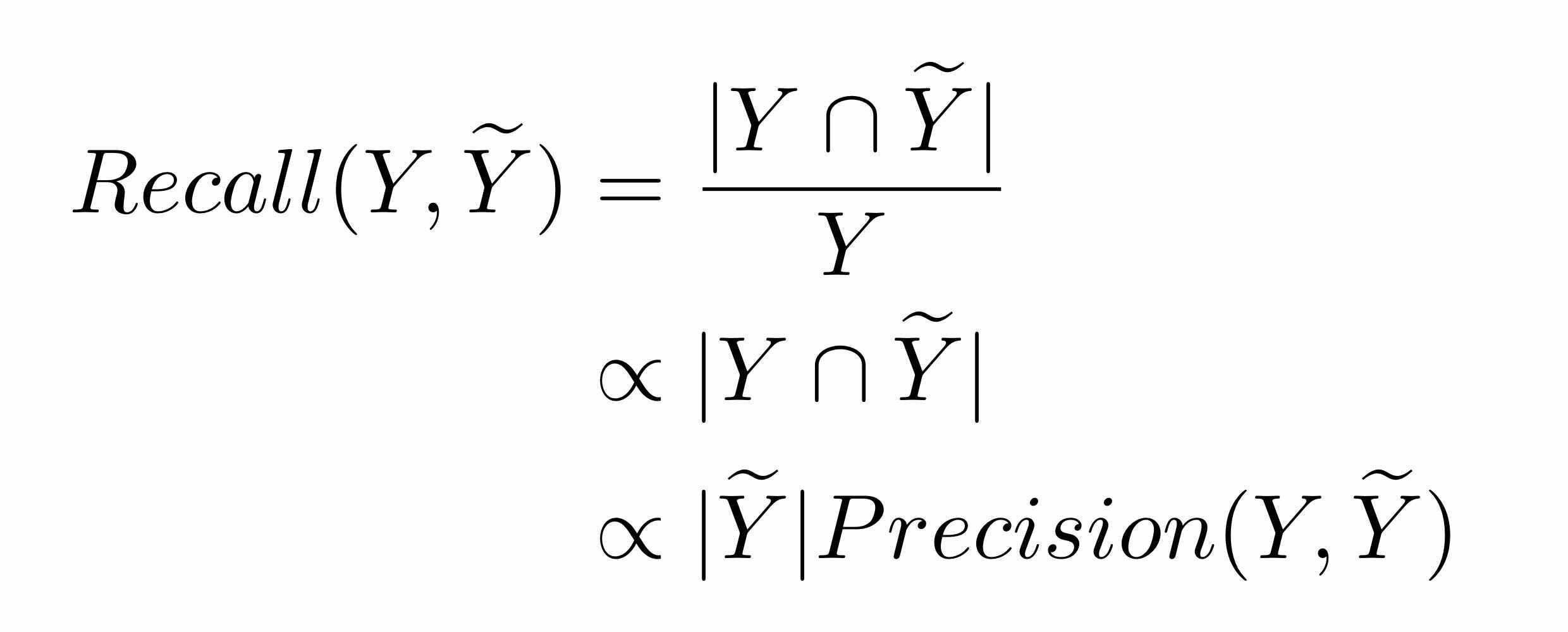
It shows that the diversity is a proxy measurement of recall and formularizes following to cover the recall side of the problem.
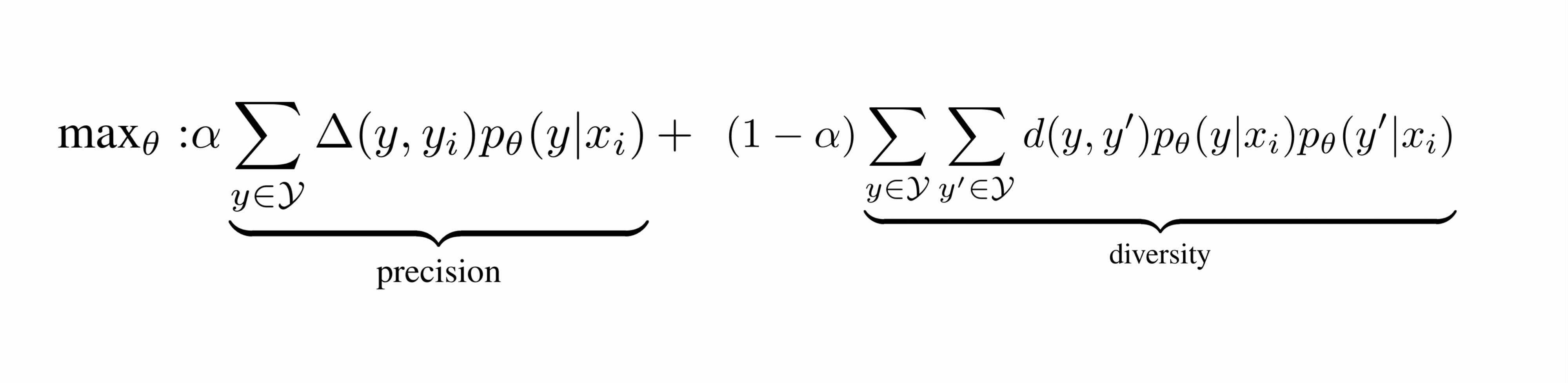
4.How did they verify it?
For image
MSCOCO datase Meteor CIDEr Spice Resnet152 pretrained on ImageNet Compare to sequence-level learning loss (SLL) and sequence-level learning with maximum entropy regularization (SLL-ME) and SLL-SLE that is it propose and compare to state-ofthe-art model and SLL-SLE.
for video
TGIF datase Meteor CIDEr Spice Resenet152 Compare to sequence-level learning loss (SLL) and sequence-level learning with maximum entropy regularization (SLL-ME) and state-ofthe-art model and SLL-SLE that is it propose.
The improvement of SLL-SLE over SLL-ME on all metrics is much larger than the improvement of SLL-ME over SLL on all metrics. So it shows effective in guiding the model to explore more plausible captions in training and consequently SLL-SLE generates more accurate captions in test.
evaluate precision and recall
precision…CIDEr recall…Div1, Div2, mBleu
- The first decoding strategy is to sample 5 captions from the model for each image (rs).
- The second decoding strategy is to beam search top 5 captions from the model for each image (bs).
SLL-SLE performs not only better on the precision side and but also better on the recall side under both random sampling and beam search decoding strategies. So its propose can generate diverse and high quality captions with sampling strategy.