A Background-induced Generative Network with Multi-level Discriminator for Text-to-Image Generation
1.What is this paper about?
背景画像とテキストから、テキストに沿った画像を生成するmulti-GAN modelを提案する。 attention mechanisms、background synthesisとmulti-level discriminatorを用いることで、SOTAを達成した。
2.What’s better than previous paper?
画像の解像度が上がった。 spatial attention mechanismとchannel-wise attentionを用いることで、textから物体を生成するタスクの精度が向上した。
3.What are important parts of technique and methods?
以下にモデルを示す。
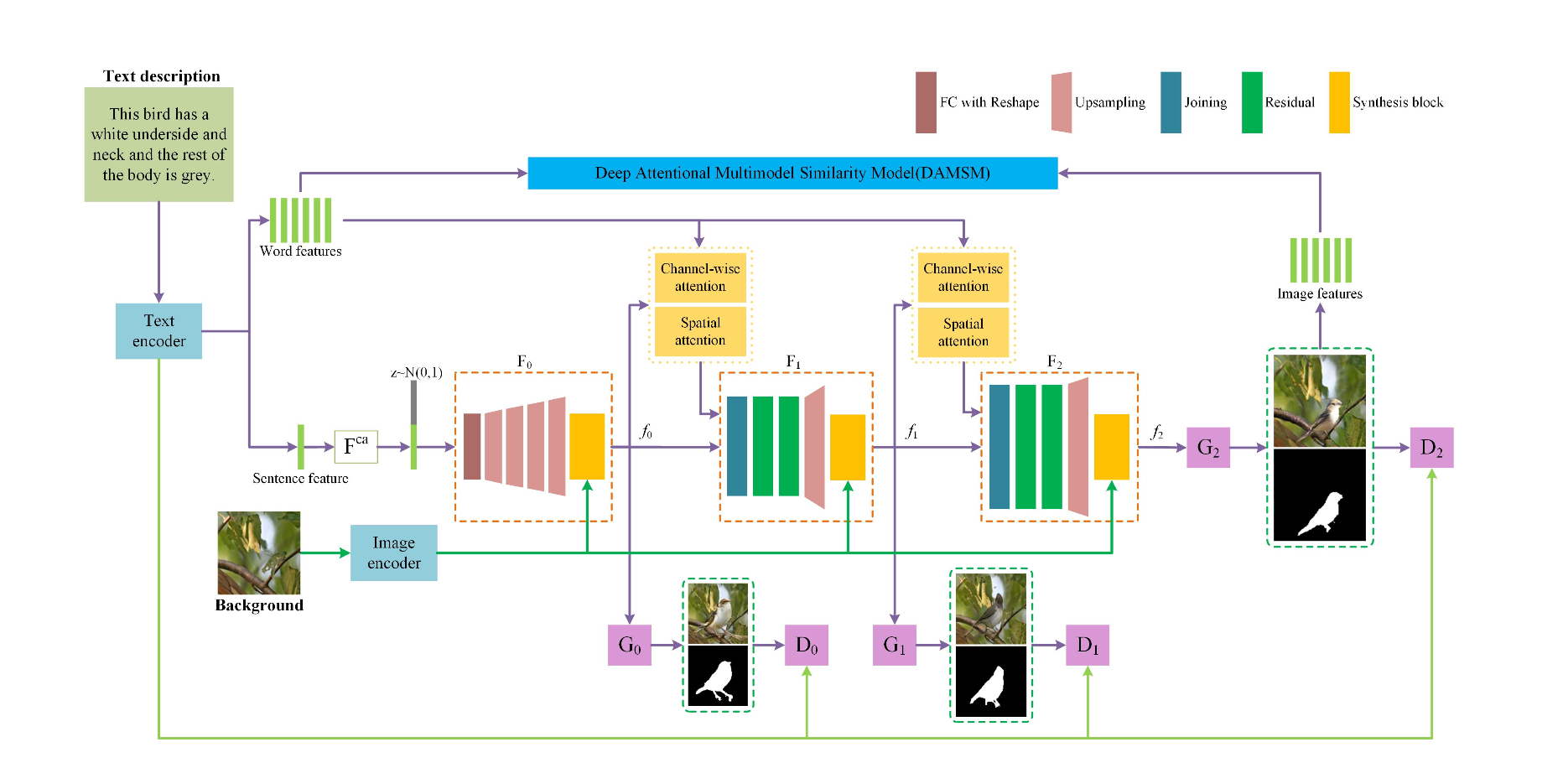
- hybrid attention mechanism
spatial attention mechanismとchannel-wise attentionを導入して、物体を生成する時に、画像をうまく生成できるようにした。
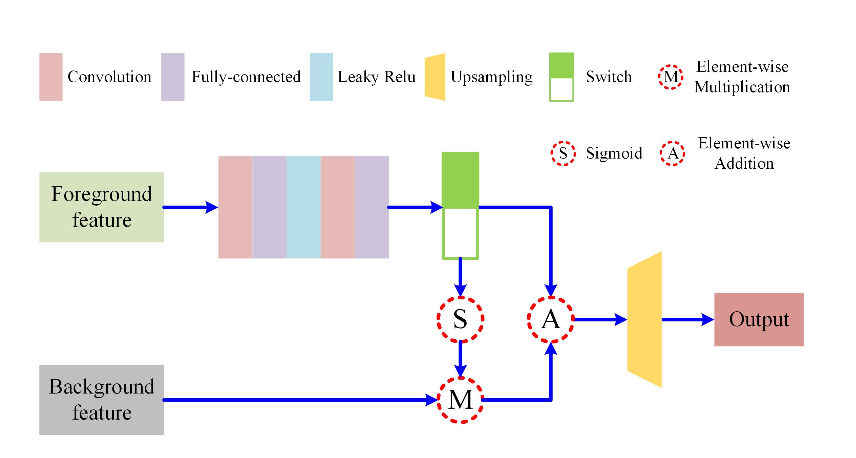
- a background-induced structure
以下のように、前景画像のfeatureと背景画像のfeatureを結びつけることによって、背景画像と前景画像をうまくmatchさせた画像生成を可能にした。
- multi-level discriminator
Multi-level discriminatorと言っているが、普通のLossがいっぱいあるdiscriminatorとなにが違うのかわからん。
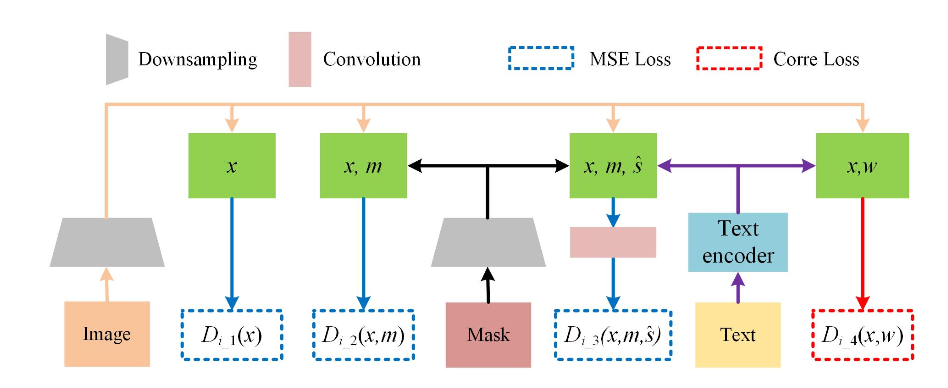
4.How did they verify it?
CUB datasetを使用して、既存研究(MC-GAN, MC-stackGAN)と定性的結果のみで比較をして評価している。
5.Is there a debate?
datasetをどのようにして学習したかなど、書いてない部分が多い。
さらに、multi-GANを使っている意味がない。

定性的結果だけでいいのか?
6.What paper should I read next?
MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis