Stochastic Image-to-Video Synthesis using cINNs
1.What is this paper about?
It proposes a novel model for understanding image-to-video synthesis based on a bijective transformation, instantiated as a cINN, between the video and image domains plus residual information.
2.What’s better than previous paper?
It frames image to video synthesis as an invertible domain transfor. By learning the residual representation, additional conditioning information can be easily incorporated to control the image-to-video synthesis process.
3.What are important parts of technique and methods?
It is overviews of its proposed framework.

It uses a conditional invertible neural network (cINN).
By understanding the image to video conversion process, it can directly control such factors, and thus control the progression of the scene depicted in the input image x0. In usually, it is fomulation of z to synthesize image to video.
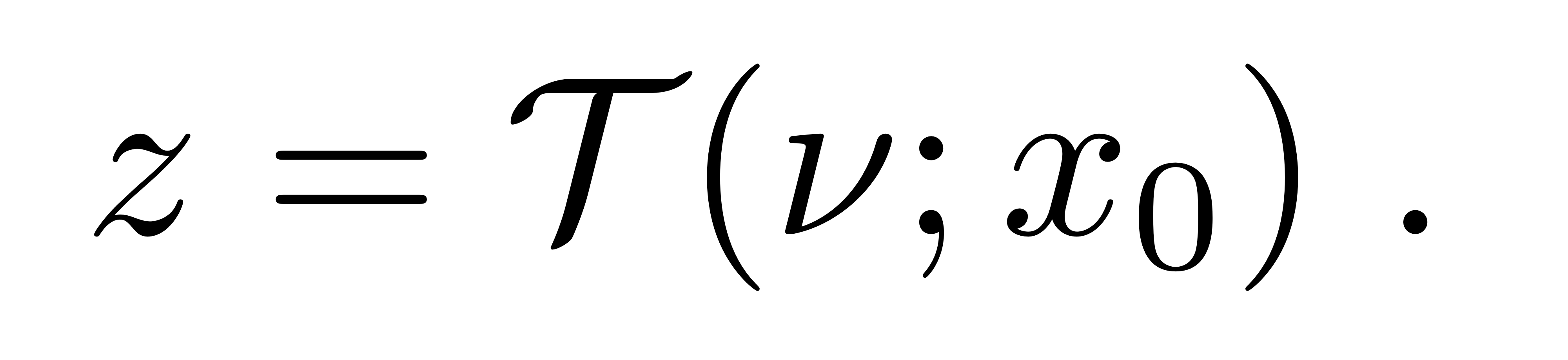
Assuming that η ∈ R dη represents such a factor, e.g. the target position of a moving object, it can model it explicitly while learning our bi-directional mapping Tθ as
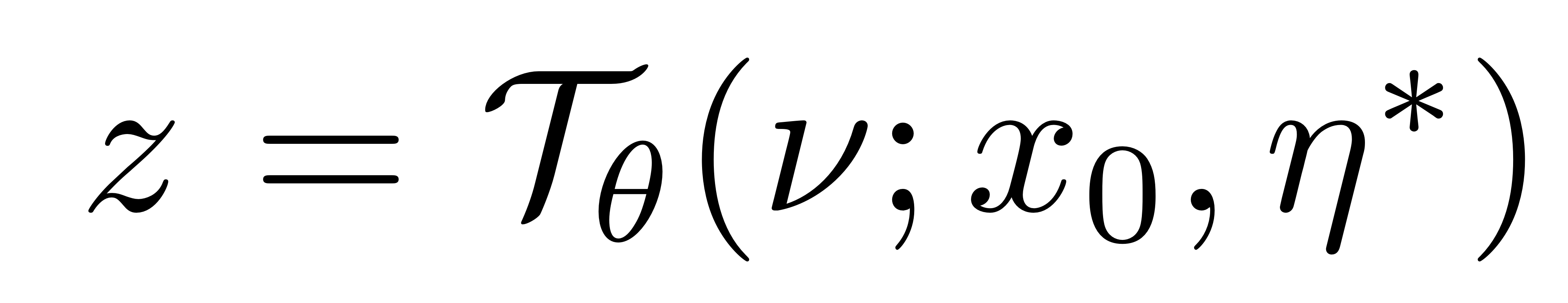
4.How did they verify it?
It was evaluated on four dataset(Landscape, Dynamic Texture DataBase(DTDB), BAIR Robot Pushing and Impersonator(iPER)), comapare with state-of-the-art method.
- Quantitative evalution
It uses the Frechet Video Distance (FVD), DTFVD, FID and Learned Perceptual Image Patch Similarity(LPIPS) as metrics. And it evaluate the diversity of synthesize video.
In all of metrics and dataset, it overpaform previouse model.
- Quantitative result Image-to-video synthesis, Controllable video synthesis and Motion transfer In thease three areas, plausible videos were obtained.
5.Is there a debate?
It needs the changing the style of input the information to control the video.